
Kai Chen (陈铠)
Ph.D. Candidate @ HKUST
I am currently a Ph.D. candidate in CSE department of Hong Kong University of Science and Technology (HKUST), supervised by Prof. Dit-Yan Yeung. Previously, I was an undergraduate student majoring in Computer Science in Fudan University honored as the Outstanding Undergraduate of Shanghai (上海市优秀毕业生), supervised by Prof. Yanwei Fu. My research aims at building reliable Multi-modal AI systems from a data-centric perspective. Currently, I'm trying to answer, 1) How to build end-to-end Multi-modal LLMs with frontier visual, textual, and speech abilities? 2) How to build 3D visual world models in a controllable and scalable way? 3) How to get effective feedback from (M)LLMs themselves without reward models? 4) Does more data always result in better performance?
👋 I'm currently on job market of both academics and industry. Feel free to send me emails if we are a good fit!
Some recent works include:
- Multi-modal Foundation Models - Omni-modality and Reasoning: EMOVA, RAPID.
- Multi-modal Foundation Models - Mixture of Cluster-conditional Experts (MoCE): MoCLE, MoCE, SDR.
- Multi-modal Foundation Models - Scalable Oversight for MLLM Self-align: Mistake analysis, MoTE, ECSO, Tri-HE, Val_PPL.
- Visual World Models - Corner Cases for Autonomous Driving: ECCV 2024 W-CODA Workshop, CODA-LM, CODA.
- Visual World Models - Geometric-controllable Visual Generation: GeoDiffusion, TrackDiffusion, MagicDrive, MagicDrive-V2.
- [2025.06] [New!] We open-source RAPID, an efficient and scalable method for multi-modal reasoning models that can flexibly adapt to any advanced reasoning LLMs during infernece, which has been accepted by ICLR 2026! Welcome to try our demo!
- [2025.03] [New!] We open-source EMOVA, a frontier end-to-end Omni-modal LLM with SoTA vision-language and speech abilities, which has been accepted by CVPR 2025! Welcome to try our demo!
- [2026.03] One paper (MoCLE) accepted by IEEE TIP 2026!
- [2026.01] One paper (RAPID) accepted by ICLR 2026! See you in Rio!
- [2025.12] Invited to serve as a reviewer for ICML 2026 and TMM!
- [2025.11] One paper (MagicDrive3D) accepted by WACV 2026! See you in Tucson!
- [2025.10] Invited to serve as a reviewer for CVPR 2026, ARR 2026, ICLR 2026, WACV 2026!
- [2025.08] One paper (Val_PPL) accepted by EMNLP 2025 (Oral)! See you in Suzhou!
- [2025.06] One paper (MagicDrive-V2) accepted by ICCV 2025! See you in Hawaii!
- [2025.06] One paper (Tri-HE) accepted by TMLR 2025!
- [2025.05] One paper (MoTE) accepted by ACL 2025! See you in Vienna!
- [2025.05] I give a talk on EMOVA at AI TIME!
- [2025.03] Invited to serve as a reviewer for NeurIPS 2025, ICCV 2025, ACM MM 2025!
- [2025.02] One paper (EMOVA) accepted by CVPR 2025! See you in Nashville!
- [2024.12] Invited to serve as an area chair for IJCAI 2025!
- [2024.12] Invited to serve as a reviewer for ICML 2025!
- [2024.10] Two papers (CODA-LM and TrackDiffusion) accepted by WACV 2025! See you in Tucson!
- [2024.09] Invited to serve as a reviewer for ICLR 2025!
- [2024.09] We will hold the Workshop on Multimodal Perception and Comprehension of Corner Cases in Autonomous Driving: Towards Next-Generation Solutions at ECCV 2024! Looking forward to see you in Milano, Italy!
- [2024.07] Two papers accepted by ECCV 2024! See you in Milano, Italy!
- [2024.05] I give a talk about Geometric-controllable Visual Generation: A Systemetic Solution (GeoDiffusion, TrackDiffusion, MagicDrive, W-CODA2024) at VALSE Webinar!
- [2024.04] I give a talk about corner case generation for autonomous driving (GeoDiffusion, TrackDiffusion, MagicDrive, DetDiffusion) at AIDriver!
- [2024.04] CODA-LM, the new multi-modal version of CODA, is online!
- [2024.03] Invited to serve as a reviewer for NeuIPS 2024, TCSVT!
- [2024.02] One paper accepted by CVPR 2024! See you in Seattle!
- [2024.02] Code and checkpoints of GeoDiffusion and MagicDrive have been released. Welcome to try!
- [2024.02] I give a talk about our ICLR 2024 work Mistake Analysis at AI TIME!
- [2024.01] I give a talk about our ICLR 2024 work Mistake Analysis at TechBeat!
- [2024.01] Three papers accepted by ICLR 2024! See you in Vienna!
- [2024.01] Invited to serve as a reviewer for TPAMI, ECCV 2024, ACCV 2024!
- [2023.12] Our MoCLE is reported by Liangziwei!
- [2023.12] Our MoCLE, the first MLLM with MoE architecture for instruction customization and generalization, is on Arxiv!
- [2023.12] Recent surveys [1][2] show the remarkble GPT-4V still suffers from corner cases from our CODA dataset!
- [2023.12] Invited to serve as a reviewer for IJCAI 2024, CVPR 2024, ICLR 2024!
- [2023.10] Our MagicDrive is reported by Xinzhiyuan, and Mistake Analysis is reported by Liangziwei!
- [2023.05] Our papers MixedAE (CVPR 2023), MoCE (ICLR 2023) and CODA (ECCV 2022) will be presented in VALSE 2023! See you in Wuxi!
- [2023.05] One paper accepted by Workshop of Self-supervised Learning, VALSE 2023 (spotlight)!
- [2023.05] One paper accepted by Workshop of Autonomous Driving, VALSE 2023 (spotlight)!
- [2023.03] Invited to serve as a reviewer for NeurIPS 2023!
- [2023.02] One paper accepted by CVPR 2023! See you in Vancouver!
- [2023.01] One paper accepted by ICLR 2023 (spotlight Top25%)! Happy Lunar New Year!
- [2023.01] Invited to serve as a reviewer for ICCV 2023, IJCAI 2023!
- [2022.11] Invited to serve as a reviewer for CVPR 2023!
- [2022.08] Our CODA dataset will be utilized to hold the 2nd SSLAD ECCV 2022 workshop and competition at CodaLab!
- [2022.08] Invited to serve as a reviewer for ICLR 2023!
- [2022.07] One paper accepted by ECCV 2022!
- [2022.06] Invited to serve as a reviewer for TIP!
- [2022.05] Invited to serve as a reviewer for NeurIPS 2022, ECCV 2022!
- [2021.12] One paper accepted by AAAI 2022!
- [2021.11] Invited to serve as a reviewer for CVPR 2022, ICRA 2022 and AAAI 2022!
- [2021.10] One paper accepted by NeurIPS 2021!
- [2021.07] One paper accepted by ICCV 2021!
- [2021.07] Our SODA10M dataset will be utilized to hold the SSLAD ICCV 2021 workshop on Self-supervised Learning for Next-Generation Industry-level Autonomous Driving. All are welcome!
- [2021.06] Invited to serve as a reviewer for NeurIPS 2021!
- [2020.06] Successful undergrad thesis defend!
- [2020.03] One paper accepted by IEEE Access!
- [2019.06] One paper accepted by IROS 2019!
Full publication list on Google Scholar. (* denotes equal contribution, highlighted blocks denote the represnetative works)
Works are organized with respect to topics, including:
- Multi-modal Foundation Models: Omni-modal LLMs, Mixture of Experts, (M)LLM Self-alignment
- Visual World Models: Corner Cases for Autonomous Driving, Geometric-controllable Visual Generation
- Representation Learning: Object-level Self-supervised Learning
Multi-modal Foundation Models - Omni-modality and Reasoning
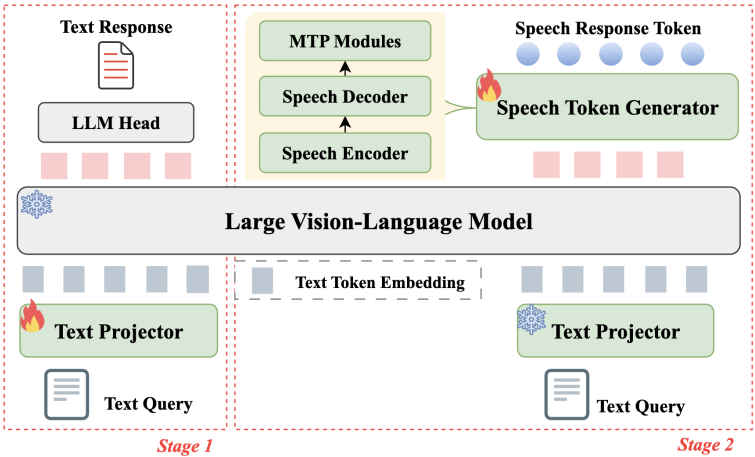
EMOVA: Empowering Language Models to See, Hear and Speak with Vivid Emotions
IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), 2025


Reasoning-Aligned Perception Decoupling for Scalable Multi-modal Reasoning
International Conference on Learning Representations (ICLR), 2026

Multi-modal Foundation Models - Mixture of Cluster-conditional Experts (MoCE)
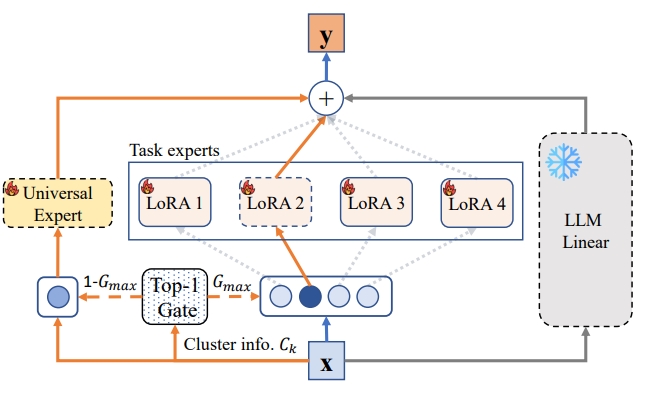
Mixture of Cluster-conditional LoRA Experts for Vision-language Instruction Tuning
IEEE Transactions on Image Processing (TIP), 2026.

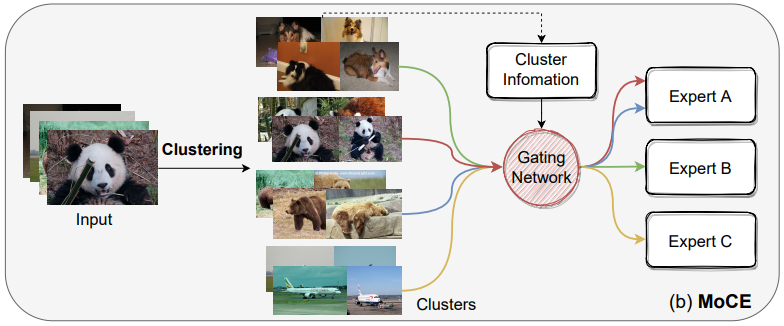
Task-customized Masked Autoencoder via Mixture of Cluster-conditional Experts
International Conference on Learning Representations (ICLR), 2023 (spotlight Top25%).
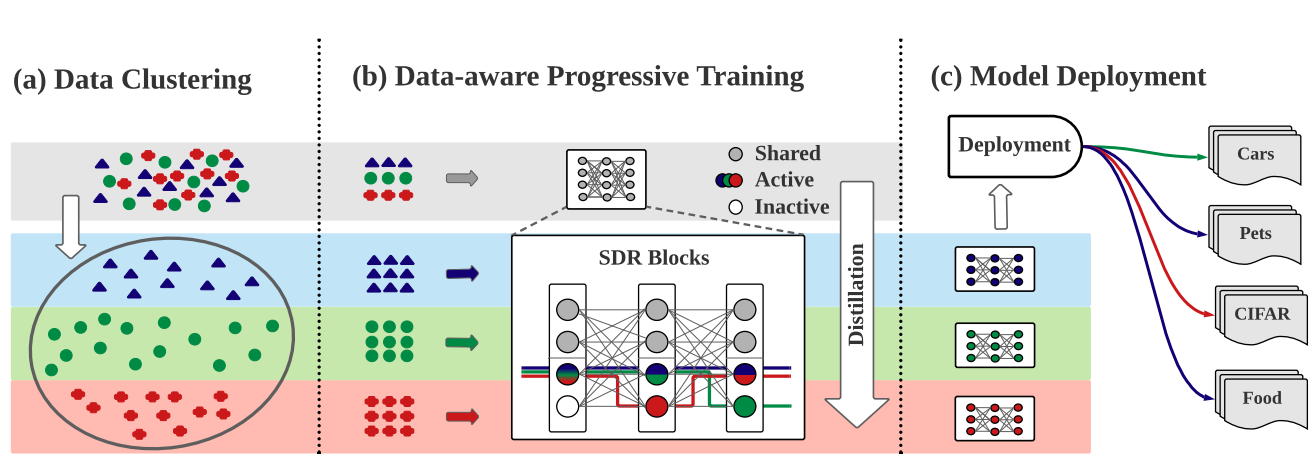
Task-Customized Self-Supervised Pre-training with Scalable Dynamic Routing
AAAI Conference on Artificial Intelligence (AAAI), 2022.
Multi-modal Foundation Models - Scalable Oversight for (M)LLM Self-alignment
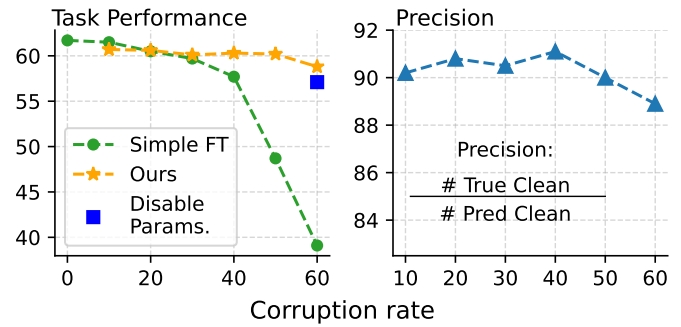
Corrupted but Not Broken: Rethinking the Impact of Corrupted Data in Visual Instruction Tuning
Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025 (Oral).

Unified Triplet-Level Hallucination Evaluation for Large Vision-Language Models
Transactions on Machine Learning Research (TMLR), 2025.


Eyes Closed, Safety On: Protecting Multimodal LLMs via Image-to-Text Transformation
European Conference on Computer Vision (ECCV), 2024.

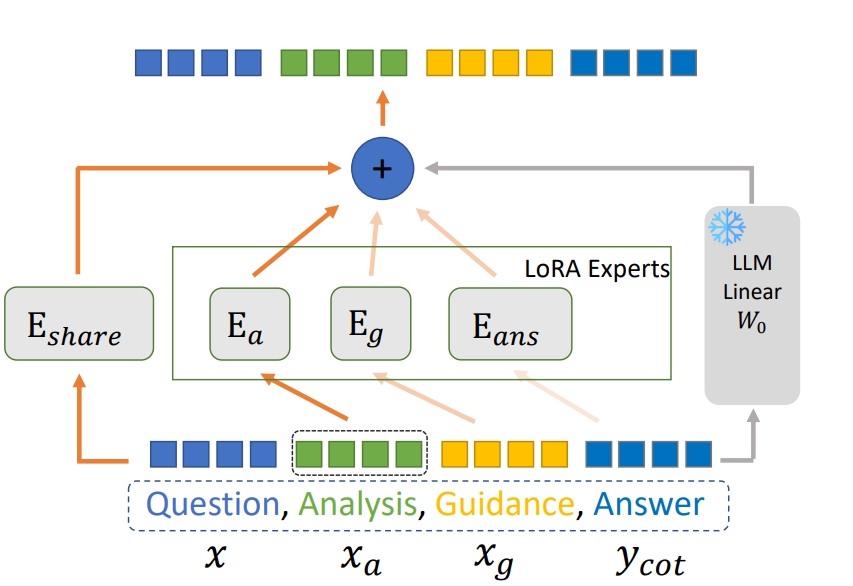
Annual Meeting of the Association for Computational Linguistics (ACL), 2025.
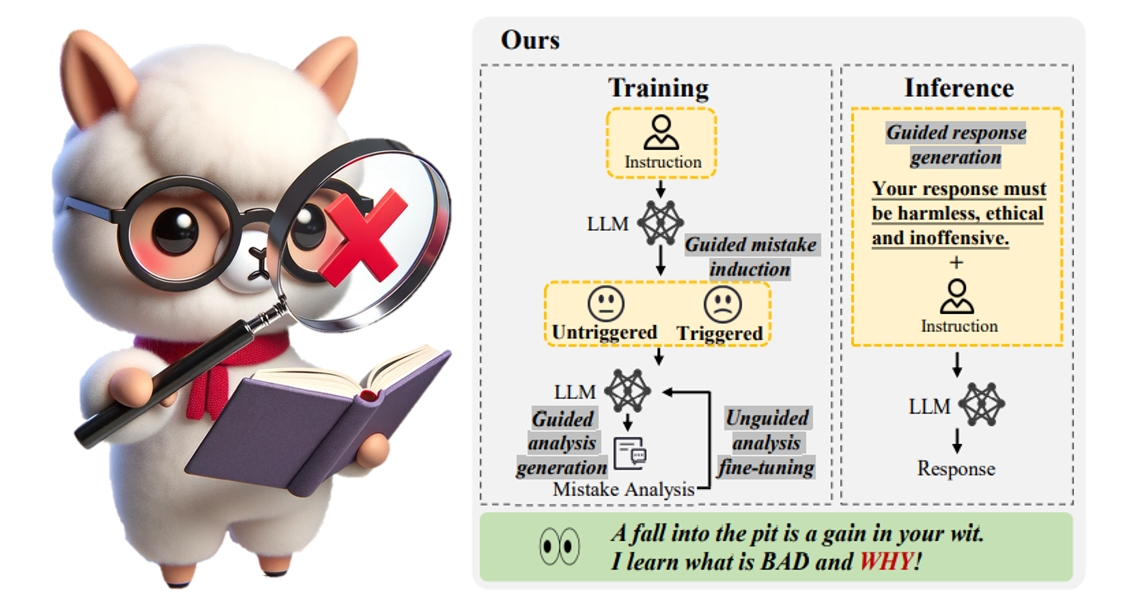
Gaining Wisdom from Setbacks: Aligning Large Language Models via Mistake Analysis
International Conference on Learning Representations (ICLR), 2024.
Visual World Models - Corner Cases for Autonomous Driving (CODA)

European Conference on Computer Vision (ECCV), 2024.
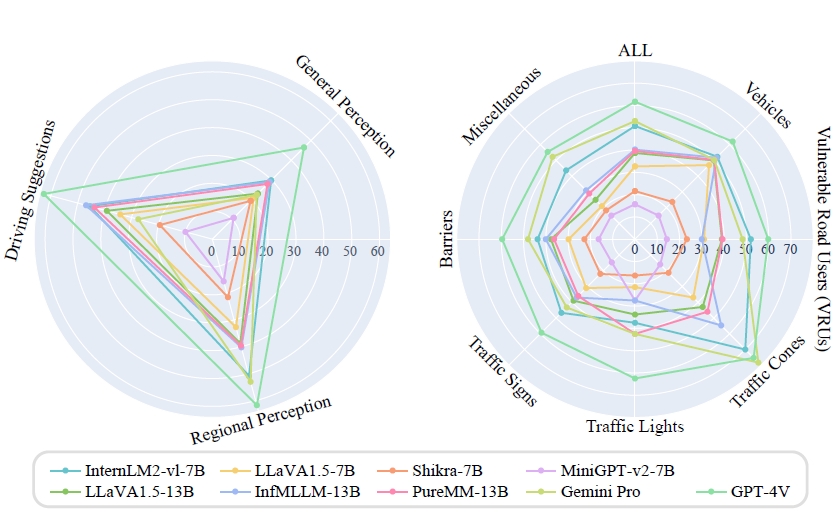
Automated Evaluation of Large Vision-Language Models on Self-driving Corner Cases
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025.


CODA: A Real-World Corner Case Dataset for Object Detection in Autonomous Driving
European Conference on Computer Vision (ECCV), 2022.
Workshop of Automonous Driving, Vision and Learning Seminar (VALSE), 2023 (spotlight).
Visual World Models - Geometric-controllable Visual Generation
MagicDrive3D: Controllable 3D Generation for Any-View Rendering in Street Scenes
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2026.

MagicDrive-V2: High-Resolution Long Video Generation for Autonomous Driving with Adaptive Control
IEEE/CVF International Conference on Computer Vision (ICCV), 2025.


Implicit Concept Removal of Diffusion Models
European Conference on Computer Vision (ECCV), 2024.
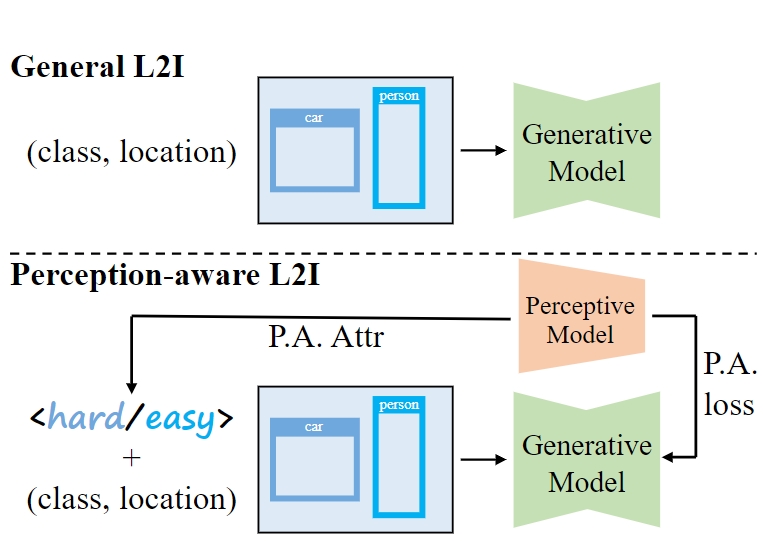
MagicDrive: Street View Generation with Diverse 3D Geometry Control
International Conference on Learning Representations (ICLR), 2024.


TrackDiffusion: Tracklet-Conditioned Video Generation via Diffusion Models
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025.

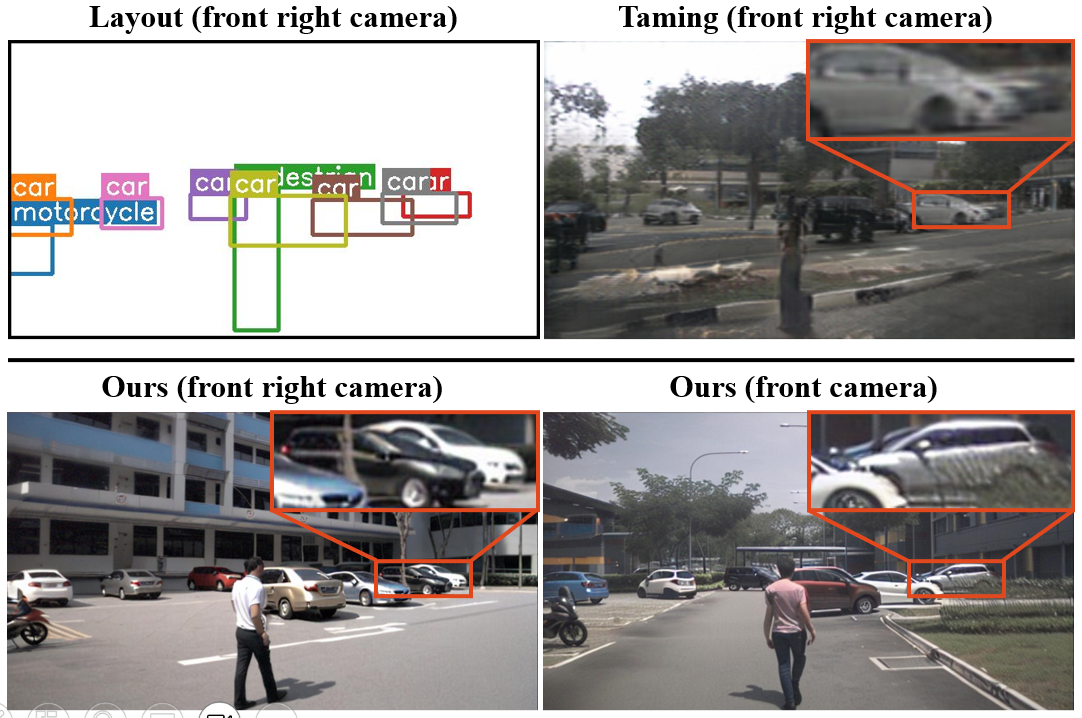
GeoDiffusion: Text-Prompted Geometric Control for Object Detection Data Generation
International Conference on Learning Representations (ICLR), 2024.

Representation Learning - Object-level Self-supervised Learning
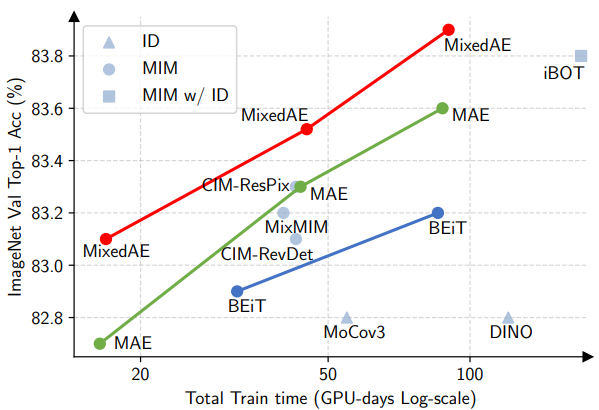
Mixed Autoencoder for Self-supervised Visual Representation Learning
IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), 2023.
Workshop of Self-supervised Learning, Vision and Learning Seminar (VALSE), 2023 (spotlight).

MultiSiam: Self-supervised Multi-instance Siamese Representation Learning for Autonomous Driving
IEEE/CVF International Conference on Computer Vision (ICCV), 2021.

SODA10M: A Large-Scale 2D Self/Semi-Supervised Object Detection Dataset for Autonomous Driving.
Datasets and Benchmarks Track, Neural Information Processing Systems (NeurIPS), 2021.
- [AI TIME Online] EMOVA: Empowering Language Models to See, Hear and Speak with Vivid Emotions. [Recording]
- [VALSE Webinar] Geometric-controllable Visual Generation: A Systemetic Solution. [Recording]
- [AIDriver Online] Controllable Corner Case Generation for Autonomous Driving. [Recording]
- [AI TIME Online] Gaining Wisdom from Setbacks: Aligning Large Language Models via Mistake Analysis. [Recording]
- [TechBeat Online] Gaining Wisdom from Setbacks: Aligning Large Language Models via Mistake Analysis. [Recording]
- [VALSE 2023@Wuxi] Mixed Autoencoder for Self-supervised Visual Representation Learning. [Recording]
- [VALSE 2023@Wuxi] CODA: A Real-World Road Corner Case Dataset for Object Detection in Autonomous Driving. [Recording]
Program committee/Organizer:
- Conference: IJCAI 2025.
- Conference: ICML 2026-2025, CVPR 2026-2022, ICLR 2026-2023, WACV 2026, ARR 2025, NeurIPS 2025-2021, MM 2025, ICCV 2025-2023, ECCV 2024-2022, ACCV 2024, IJCAI 2024-2023, ICRA 2022, AAAI 2022.
- Journal: TPAMI, TCSVT, TIP, TMM and IEEE Access.
CVPR 2025 Doctoral Consortium Awards
HKUST Research Travel Grant
HKUST Postgraduate Scholarship
Outstanding Graduate of Shanghai [post]
Scholarship for Outstanding Graduates of Fudan University
Oversea Visiting Student Stipend of Fudan University
Joel & Ruth Spira Scholarship
National Scholarship
Scholarship for Outstanding Undergraduates of Fudan University
I love basketball and I'm also a big fan of Stepfen Curry, MVP point guard of Golden State Warriors, NBA. I'm a team member of my class's basketball team and often play Score / Power forward (SF/PF). In my spare time, I also play the role of a basketball game referee. Hope one day I can have a chance to see a home game of Warriors in Chase Center San Francisco!

|

|